在當今移動互聯網高速發展的時代,Google、Amazon、Netflix等全球頂尖互聯網公司早已將SRE(Site Reliability Engineering,站點可靠性工程)作為其技術架構的核心支柱。這一角色的興起并非偶然,而是源于移動互聯網研發和維護模式從“傳統運維”到“SRE”的深刻變革。SRE之所以比傳統運維更搶手,主要基于以下幾個關鍵原因:
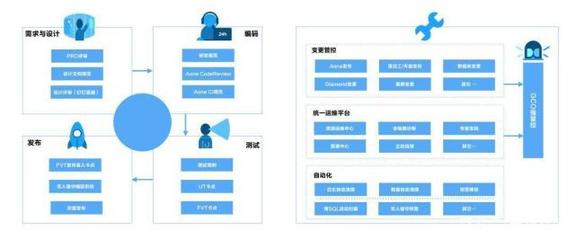
SRE實現了研發與運維的深度融合。傳統運維往往扮演“救火隊”角色,在研發完成后介入,被動響應故障。而SRE從產品設計初期就參與其中,將可靠性、可擴展性和自動化作為核心設計原則。他們不僅負責維護系統穩定,更通過編寫代碼、設計架構來主動預防問題。例如,通過自動化部署、監控告警和故障自愈系統,SRE能大幅減少人為操作失誤,提升服務可用性。在移動互聯網領域,用戶對App的穩定性和響應速度要求極高,SRE這種“防患于未然”的理念,正是保障億級用戶流暢體驗的關鍵。
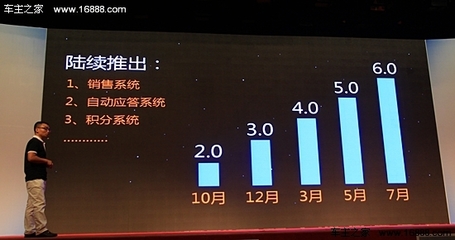
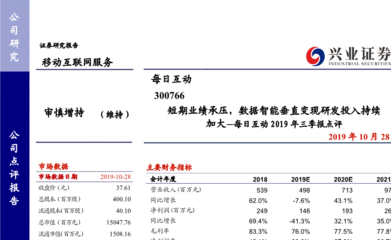
SRE以工程化方法量化運維目標。傳統運維通常依賴經驗判斷,而SRE引入如SLI(服務等級指標)、SLO(服務等級目標)和SLA(服務等級協議)等精確度量體系。例如,設定“99.99%的API請求響應時間低于100毫秒”作為SLO,并通過監控數據持續追蹤。這使得運維工作從模糊的“保持系統穩定”轉變為可衡量、可優化的工程任務。在移動互聯網場景中,從用戶登錄、支付到內容加載,每一個環節的延遲都可能造成用戶流失,SRE的數據驅動方法能精準定位瓶頸,提升業務競爭力。
SRE強調自動化與創新。傳統運維常陷入重復性手工操作,如服務器配置、日志排查等。SRE則秉承“通過自動化消除瑣事”的原則,將至少50%時間投入開發工具和平臺,以提升效率。例如,開發統一監控平臺、自動化擴容系統和混沌工程工具,模擬故障以增強系統韌性。移動互聯網服務需快速迭代,每日可能部署數十次更新,SRE的自動化能力能確保發布既敏捷又可靠。
SRE推動文化變革,倡導“共享責任”。在傳統模式中,研發與運維易形成對立;而SRE團隊通常由兼具開發與運維技能的工程師組成,他們與研發團隊共同承擔服務可靠性的責任。這種協作文化加速了問題解決,并鼓勵從故障中學習。例如,通過建立“事后分析”機制,將每次事故轉化為系統改進的機會。對于移動互聯網公司,這種文化能快速適應市場變化,降低運維成本。
市場需求的爆發加劇了SRE的搶手程度。隨著云計算、微服務和容器化技術的普及,系統復雜度呈指數級增長,企業急需能駕馭分布式架構的復合型人才。SRE不僅懂運維,還精通編程、網絡和數據分析,其稀缺性推高了薪資和職業前景。據統計,國內外頭部互聯網公司的SRE崗位薪資常比傳統運維高出30%-50%,且晉升路徑更廣。
SRE的崛起標志著運維領域從“手工勞動”到“智能工程”的范式轉移。在移動互聯網時代,它不僅是技術崗位,更是保障業務持續增長的戰略角色。對于企業和從業者而言,擁抱SRE意味著更高效、更可靠的數字未來——這正是為什么SRE正成為技術世界中一顆耀眼的明星。